Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
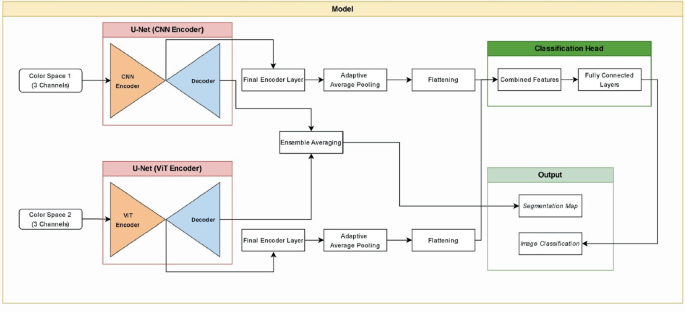
A Combined Model of CNN and ViT for Deepfake Image Detection -Journal ...
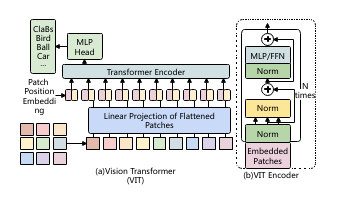
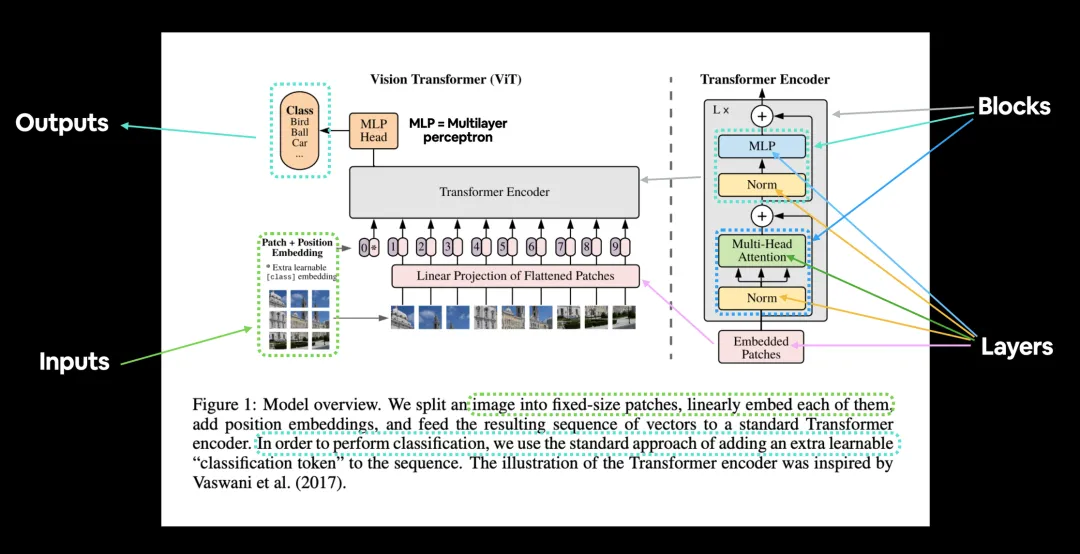
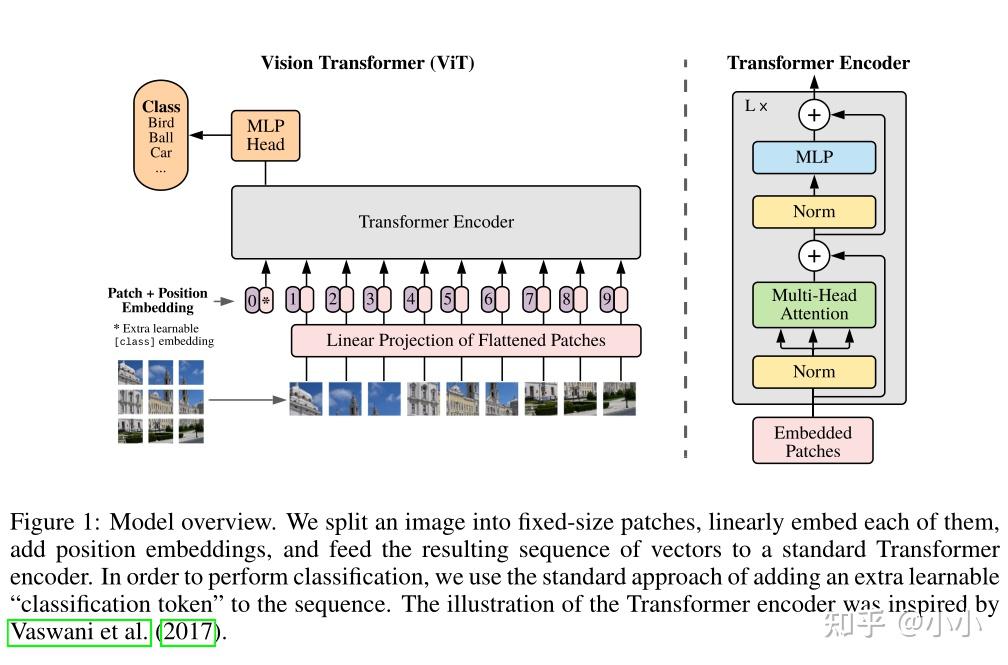
ViT model and transformer encoder [34] | Download Scientific Diagram
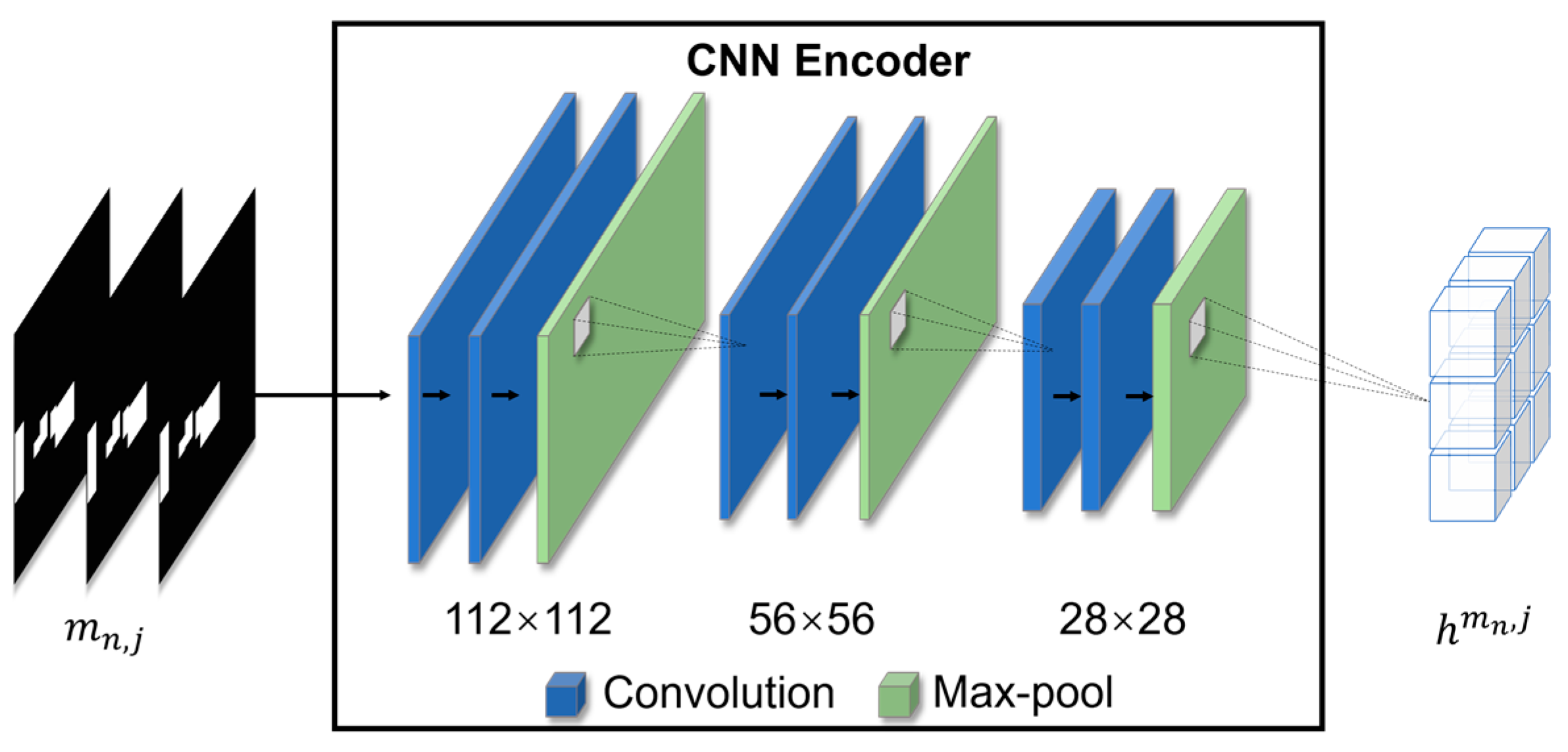
Encoder CNN structure. | Download Scientific Diagram
The ViT Encoder Architecture | Download Scientific Diagram
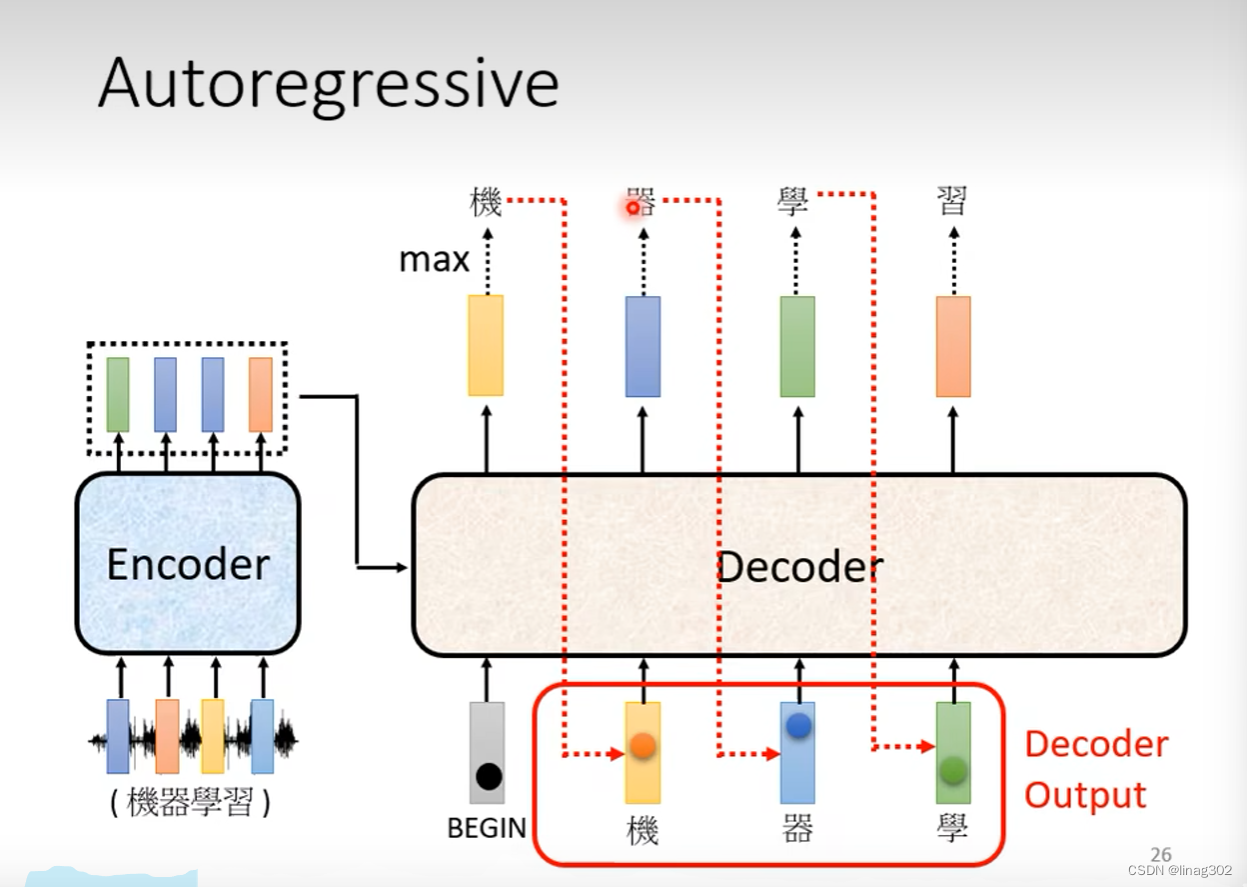
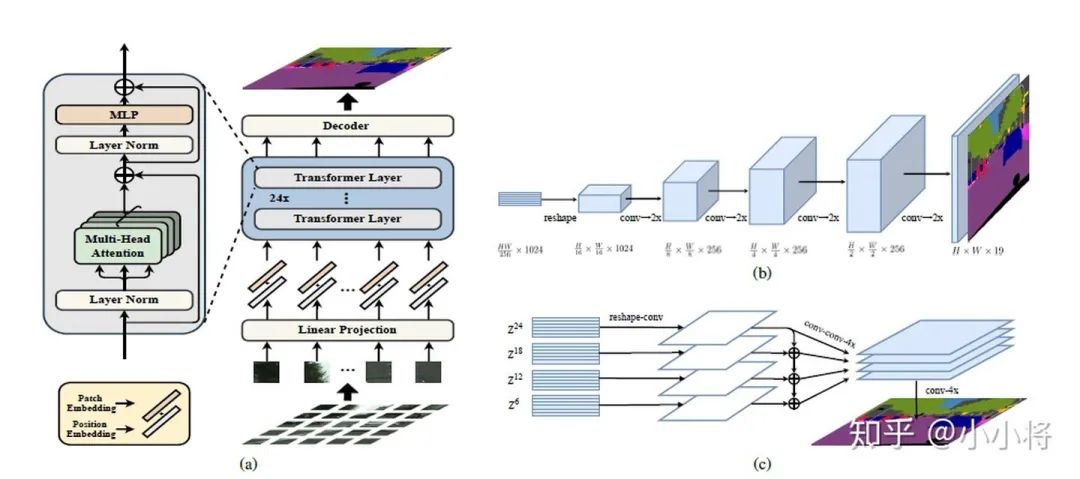
The proposed MResTNet architecture uses a ViT encoder and decoder ...
Traffic Accident Detection Using Background Subtraction and CNN Encoder ...
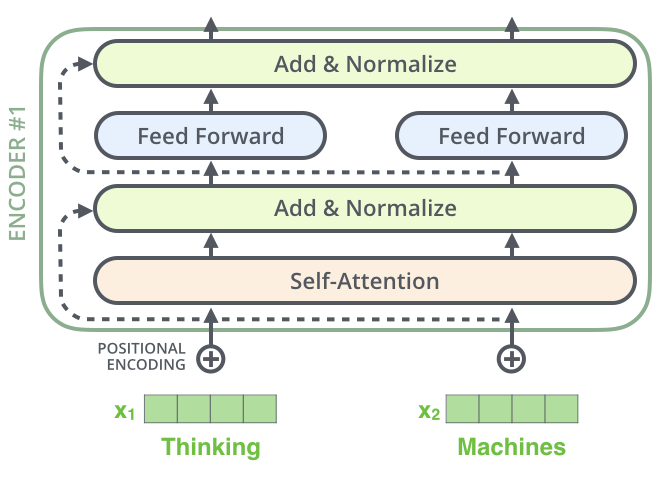
VIT (Vision Transformer) and VIT Encoder | EdrawMax Templates
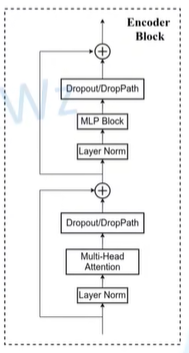
Architecture of the ViT encoder block | Download Scientific Diagram
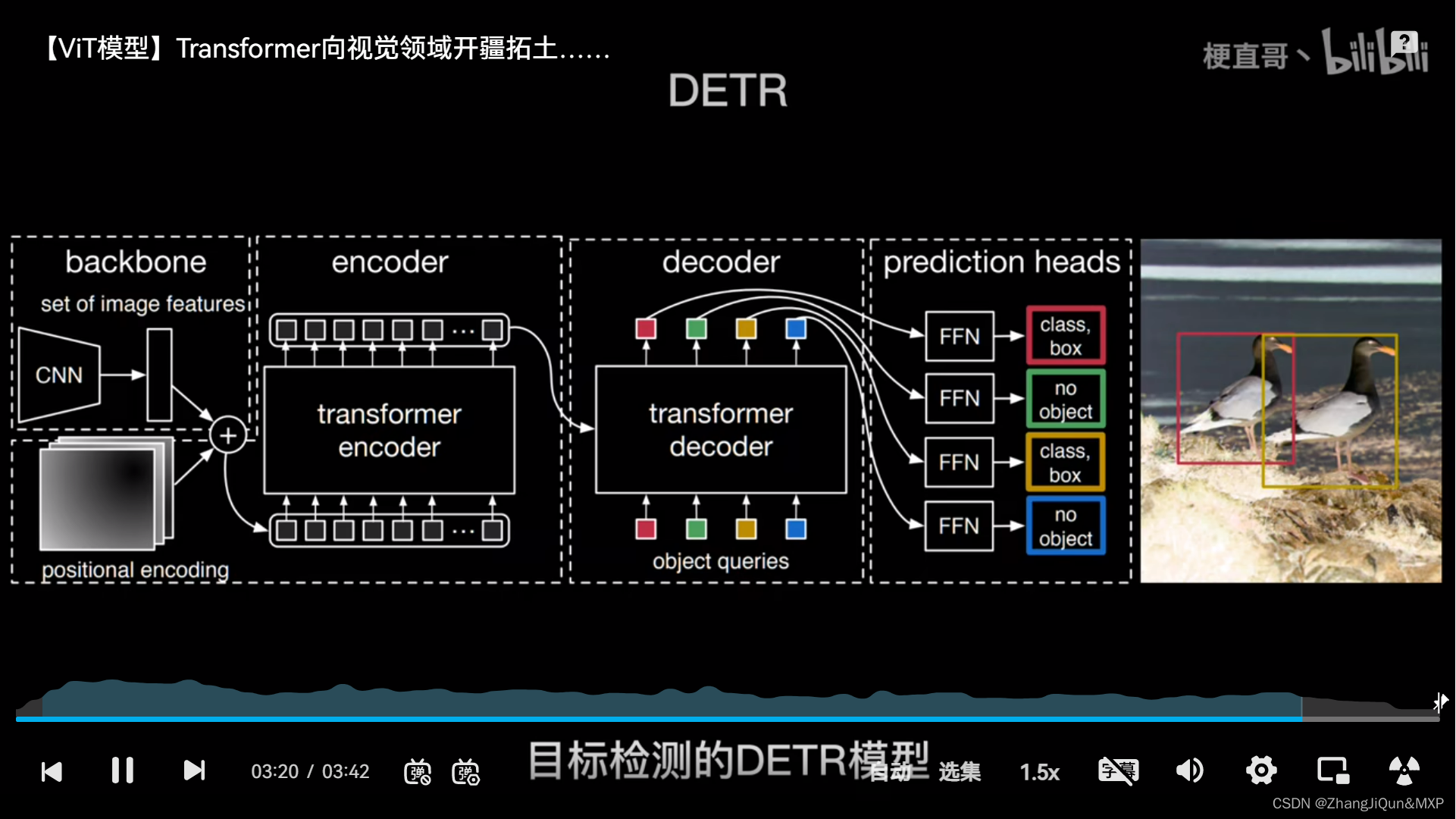
Figure 1 from Combined CNN Transformer Encoder for Enhanced Fine ...
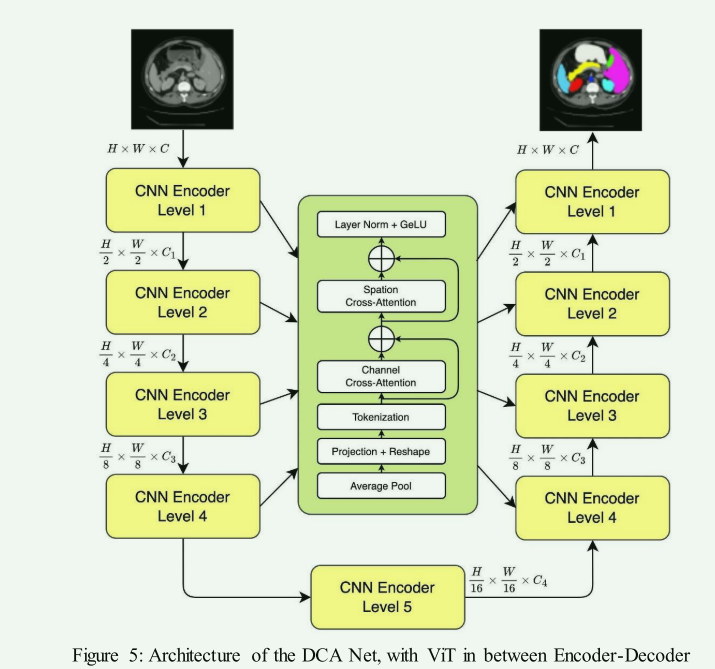
FIGURE Detailed structure blueprint of the CNN Encoder (A), Decoder ...
a ViT architecture for image classification, b transformer encoder ...
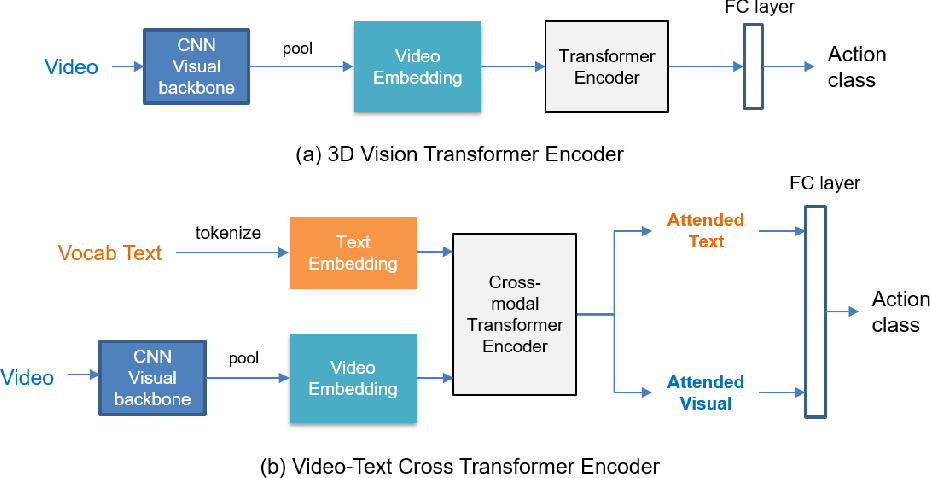
Detailed architecture for the frame-synchronous CNN encoder (left) and ...
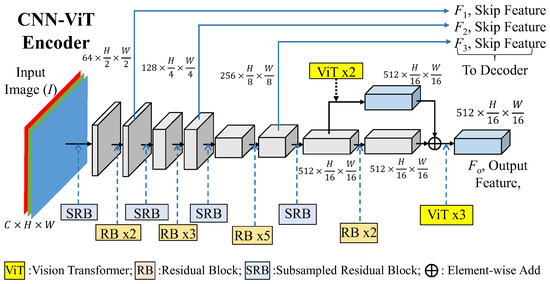
MarketNet: Multicolor Hybrid CNN and ViT for Multitask Image ...
The ViT-based encoder architecture. The ViT model takes an input image ...
CNN Attention Enhanced ViT Network for Occluded Person Re-Identification
CNN vs. ViT - Speaker Deck
A Performance Comparison of Japanese Sign Language Recognition with ViT ...
CNN 과 ViT가 어떤 차이가 있는지를 보여주는 글 입니다. 요약하자면, CNN은 수용 필드로 인해 글로벌 맥락을 포착하는 데 ...
The architecture of the ViT-based encoder and decoder, where both ...
CNN 到 Transformers 演变和vit(Vision Transformer)解读 - 知乎
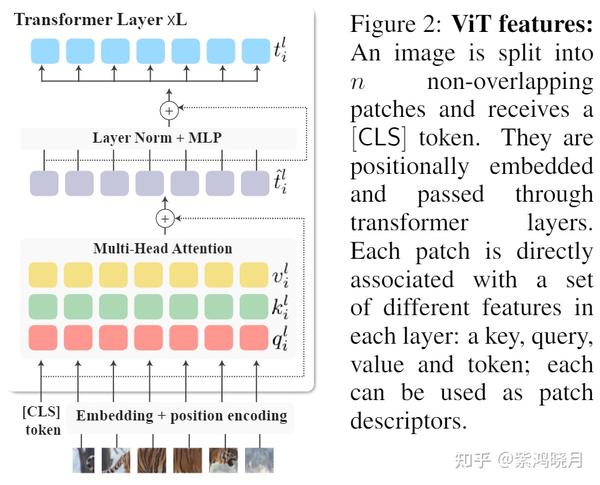
Deep ViT Features as Dense Visual Descriptors - 知乎
Learning CNN on ViT: A Hybrid Model to Explicitly Class-specific ...
The architecture of the CNN encoder. | Download Scientific Diagram
(a) Encoder of Vision Transformer (ViT) [18] inspired by the encoder of ...
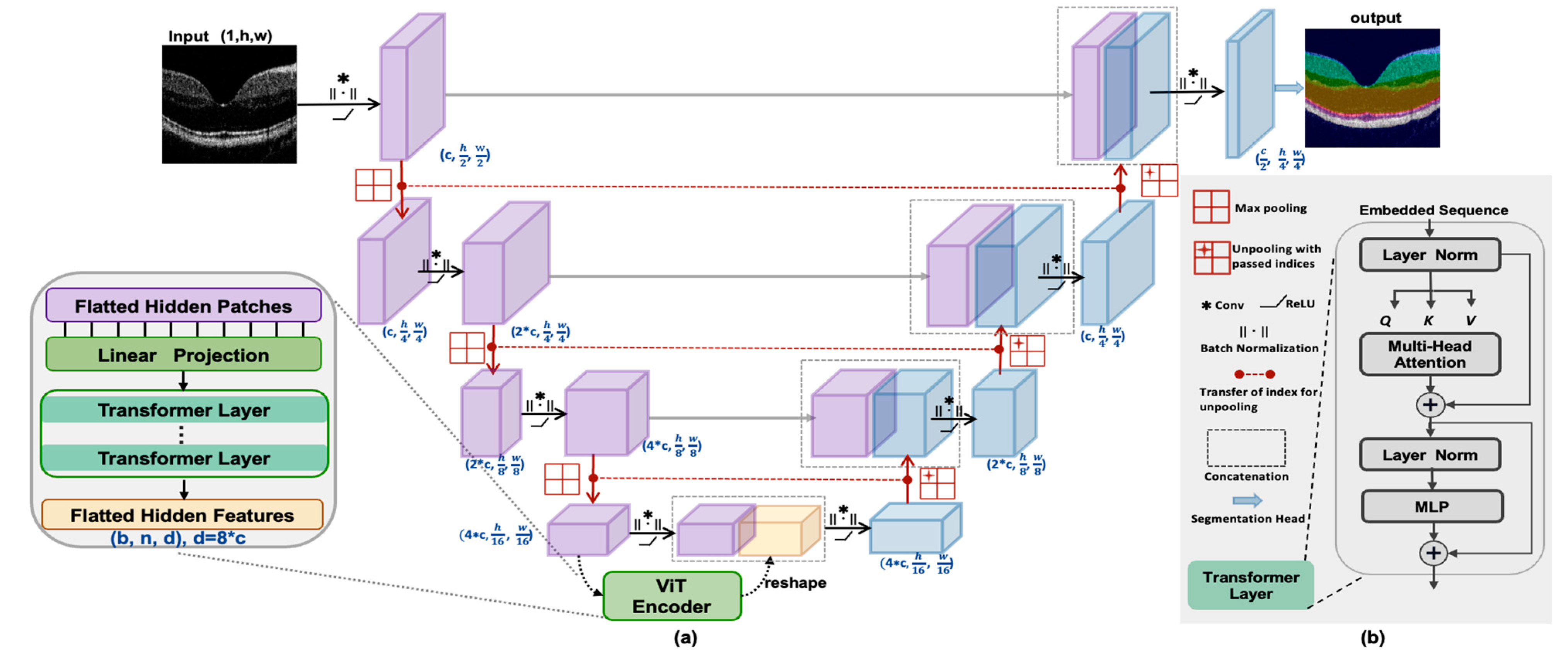
TranSegNet: Hybrid CNN-Vision Transformers Encoder for Retina ...
Overview of the proposed solution. The used ViT is the base version ...
The CNN encoder. The yellow block depicts the CNN layer, containing ...
General structure of the CNN Encoder-Decoder, contains a clean ...
Overview of the proposed STA-Former. The encoder consists of a layered ...
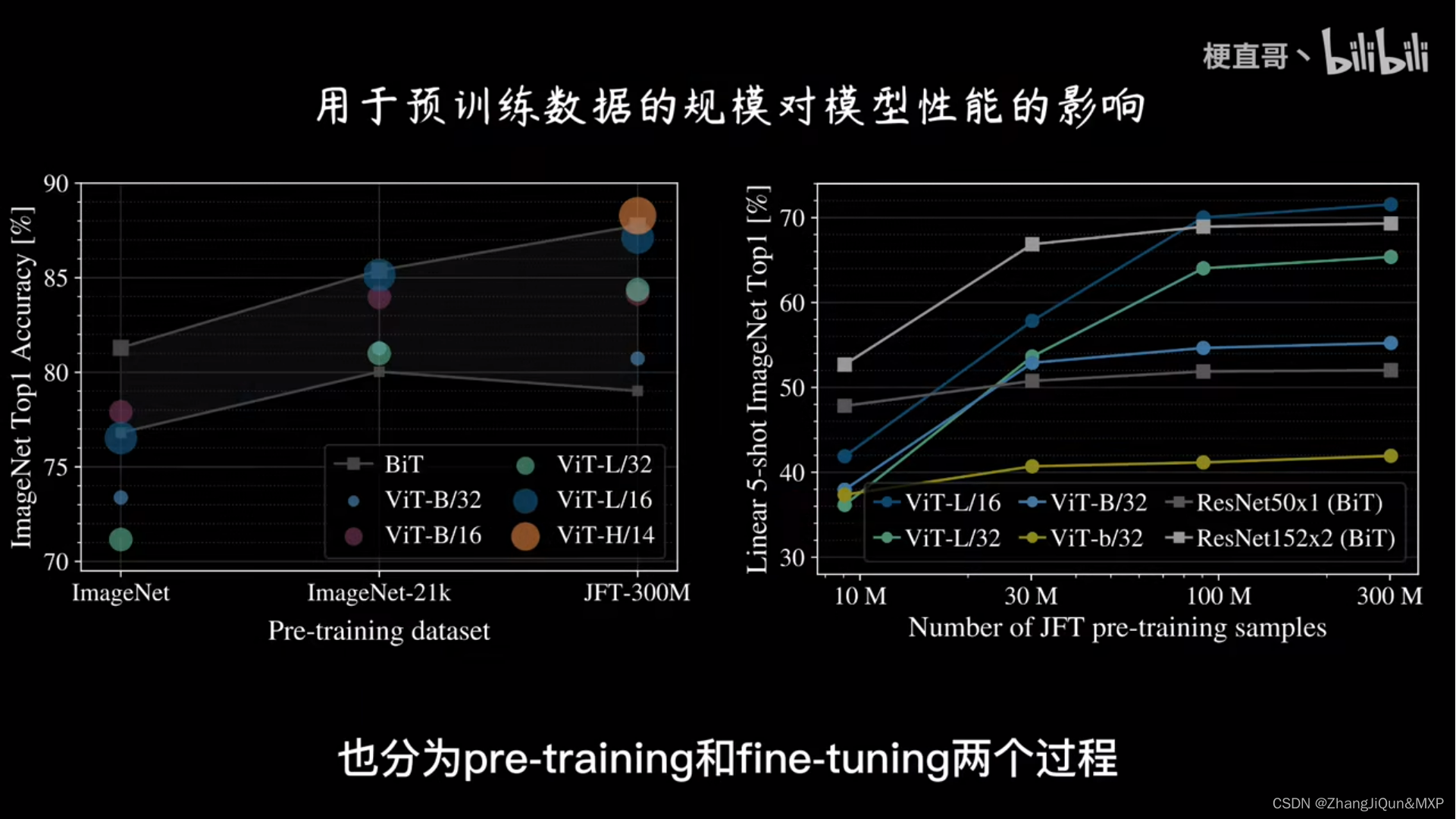
The encoder and decoder configurations. ViT-series refers to three ...
The structure of ViT-V. The network consists of Transformer Encoder ...
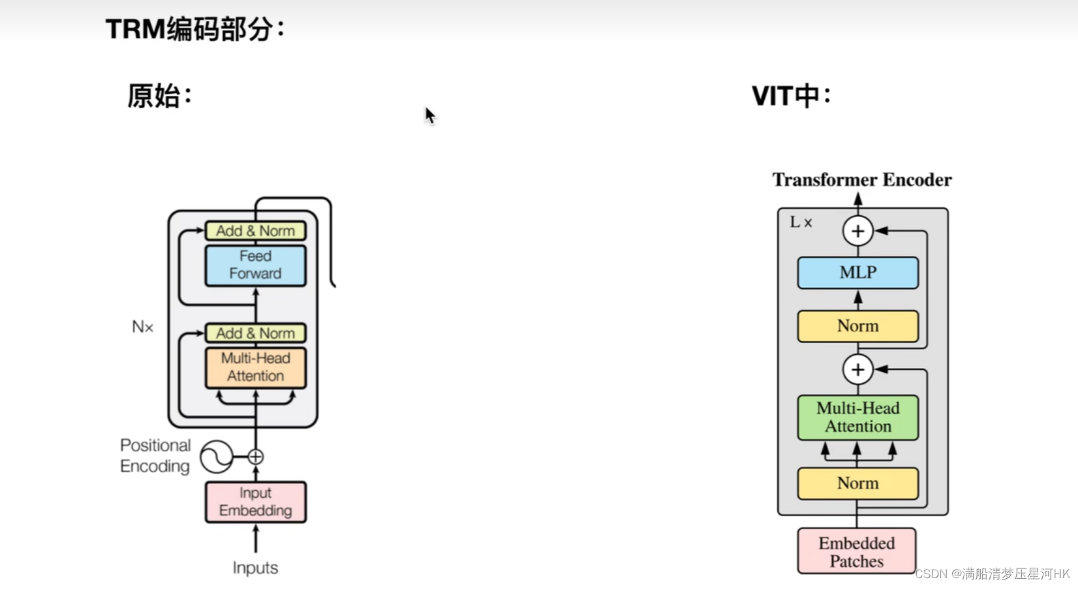
VIT transformer详解-CSDN博客
Overall architecture of the ViT encoder. | Download Scientific Diagram
GitHub - kangchengX/CNN-ViT: Implements MobileViT and ViT from scratch ...
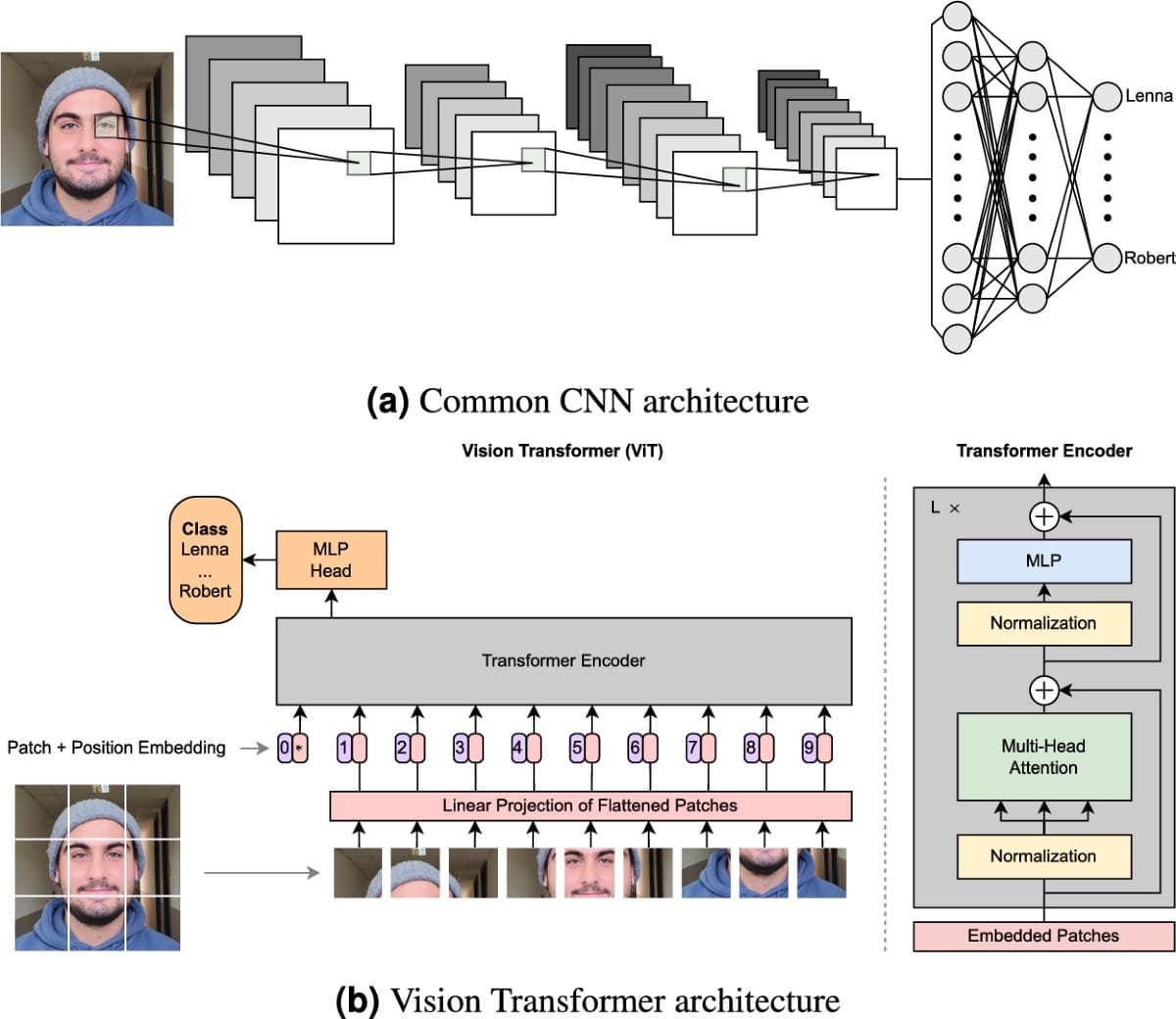
CNN vs. Vision Transformer: A Practitioner’s Guide to Selecting the ...
Residual Vision Transformer and Adaptive Fusion Autoencoders for ...
Vision Transformer:视觉Transformer对CNN的降维打击
Overview of the proposed n-CNN-ViT architecture. The model is composed ...
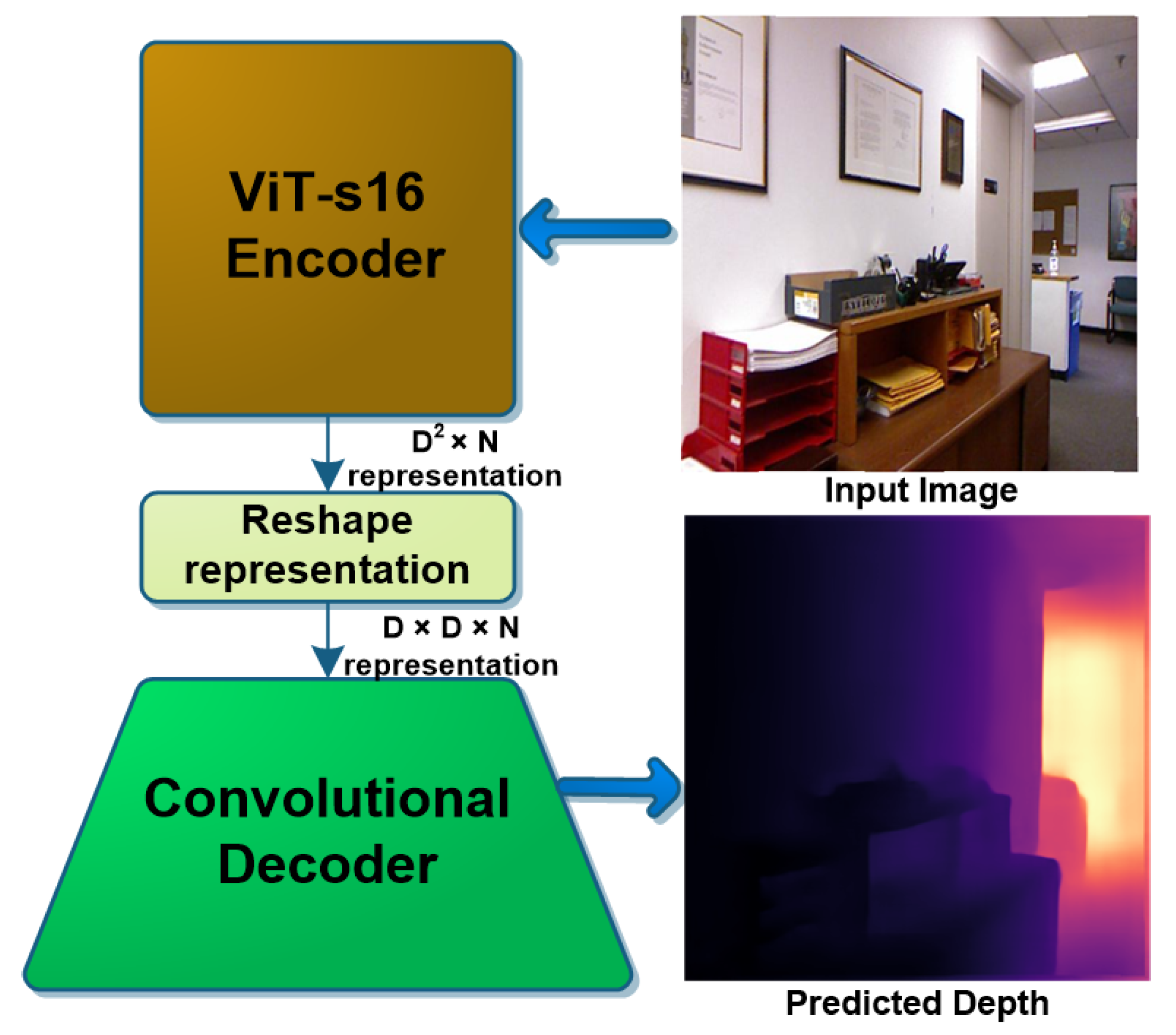
RT-ViT: Real-Time Monocular Depth Estimation Using Lightweight Vision ...
Proposed architecture overview. Input image is processed by Max-ViT ...
【论文阅读笔记】A Recent Survey of Vision Transformers for Medical Image ...
(a) The schematic of CNN-based image encoder. (b) The schematic of ...
The architecture of the CNN-based autoencoder (CNN-AE) | Download ...
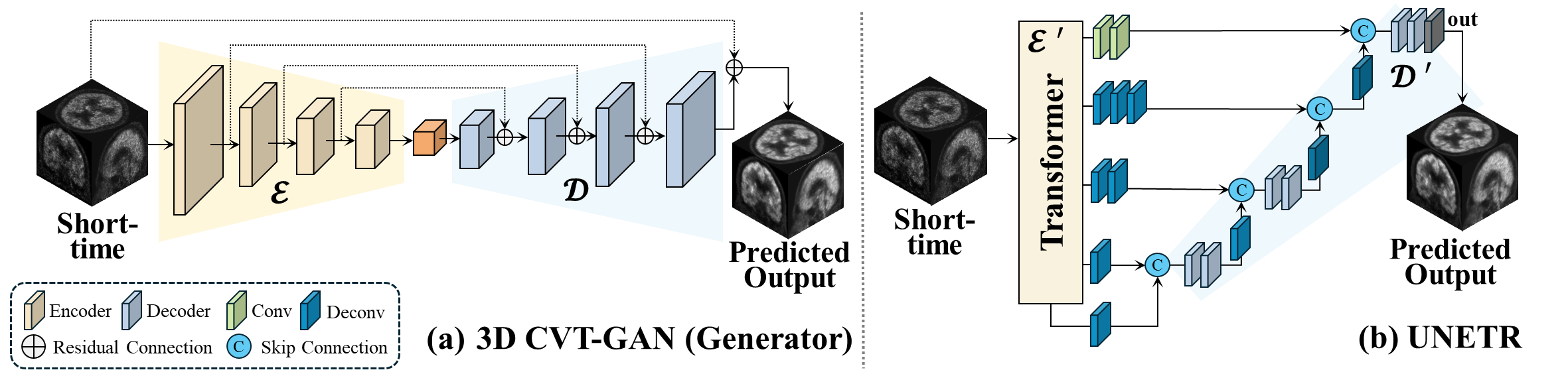
Architecture of ViT-based UNETR directly connected to a CNN-based ...
Transformer(四)ViT and SimpleViT - 知乎
Từ A-Z về Vision Transformer: Kiến trúc, cơ chế hoạt động, ứng dụng
MICV
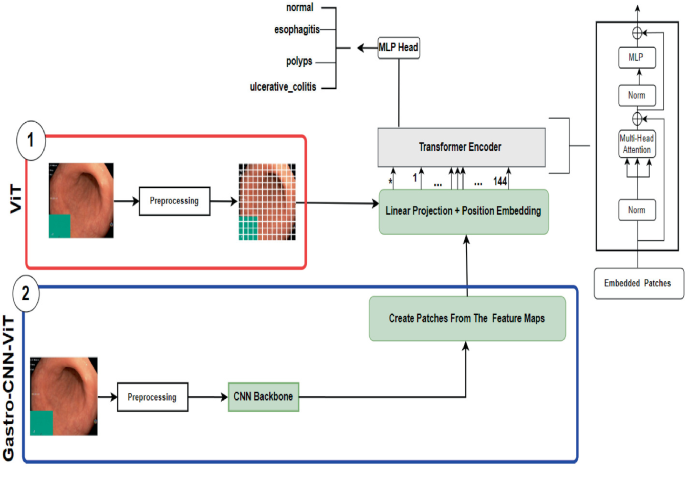
Gastro-CNN-VIT: Vision Transformer and Deep CNNs for Detecting GI ...
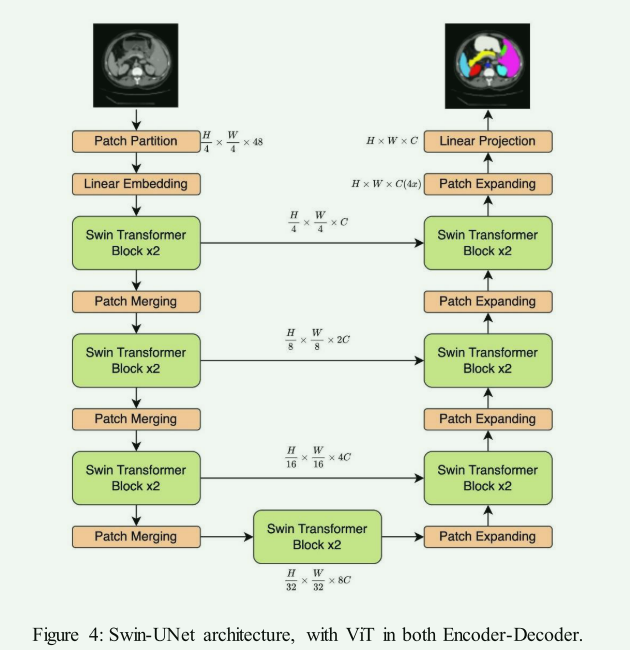
An illustration of the proposed multi-level TransUNet in this paper ...
混合CNN和ViT的自监督知识蒸馏单目深度估计方法
CvT:微软提出结合CNN的ViT架构 | 2021 arxiv-CSDN博客
Vision Transformers (ViT) Explained | AI Tutorial | Next Electronics
Vision Transformer:打破CNN垄断,全局注意力机制重塑计算机视觉范式 - 技术栈
ViT模型架构和CNN区别_vit transformer比cnn-CSDN博客
Conv-ViT: A Convolution and Vision Transformer-Based Hybrid Feature ...
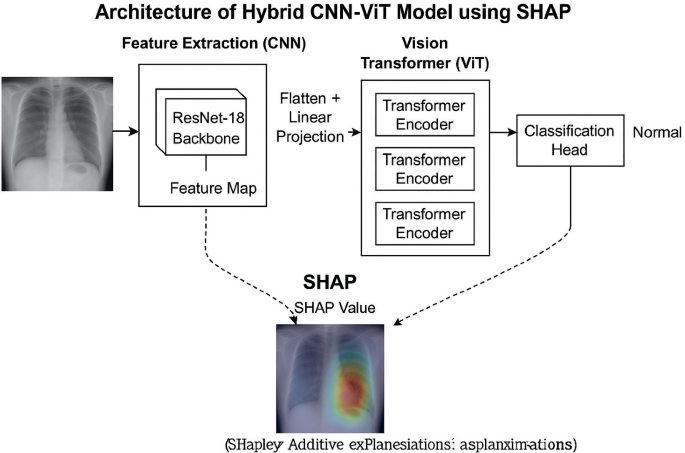
Explainable AI in Healthcare: A Hybrid CNN-ViT Approach for Pneumonia ...
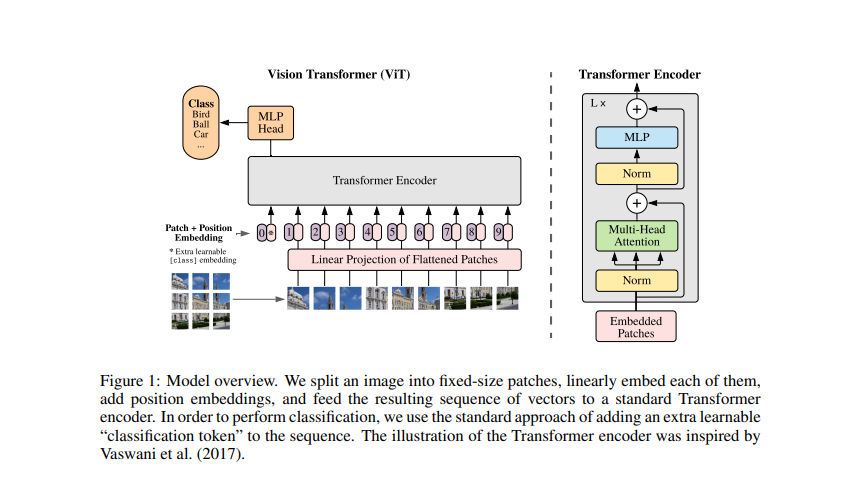
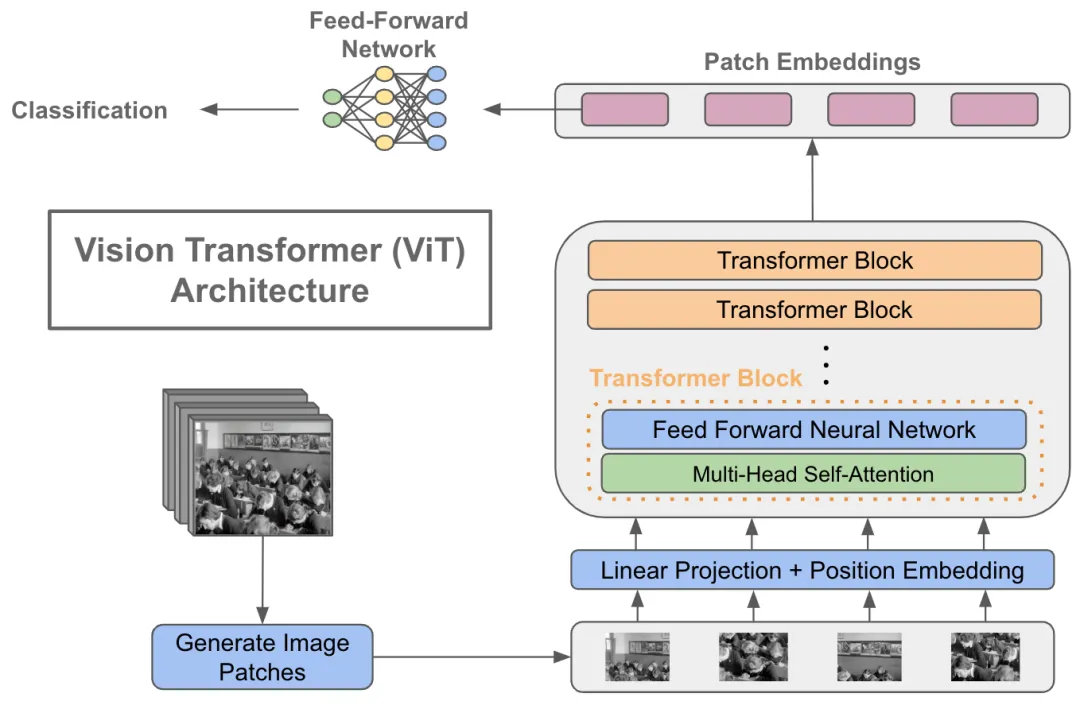
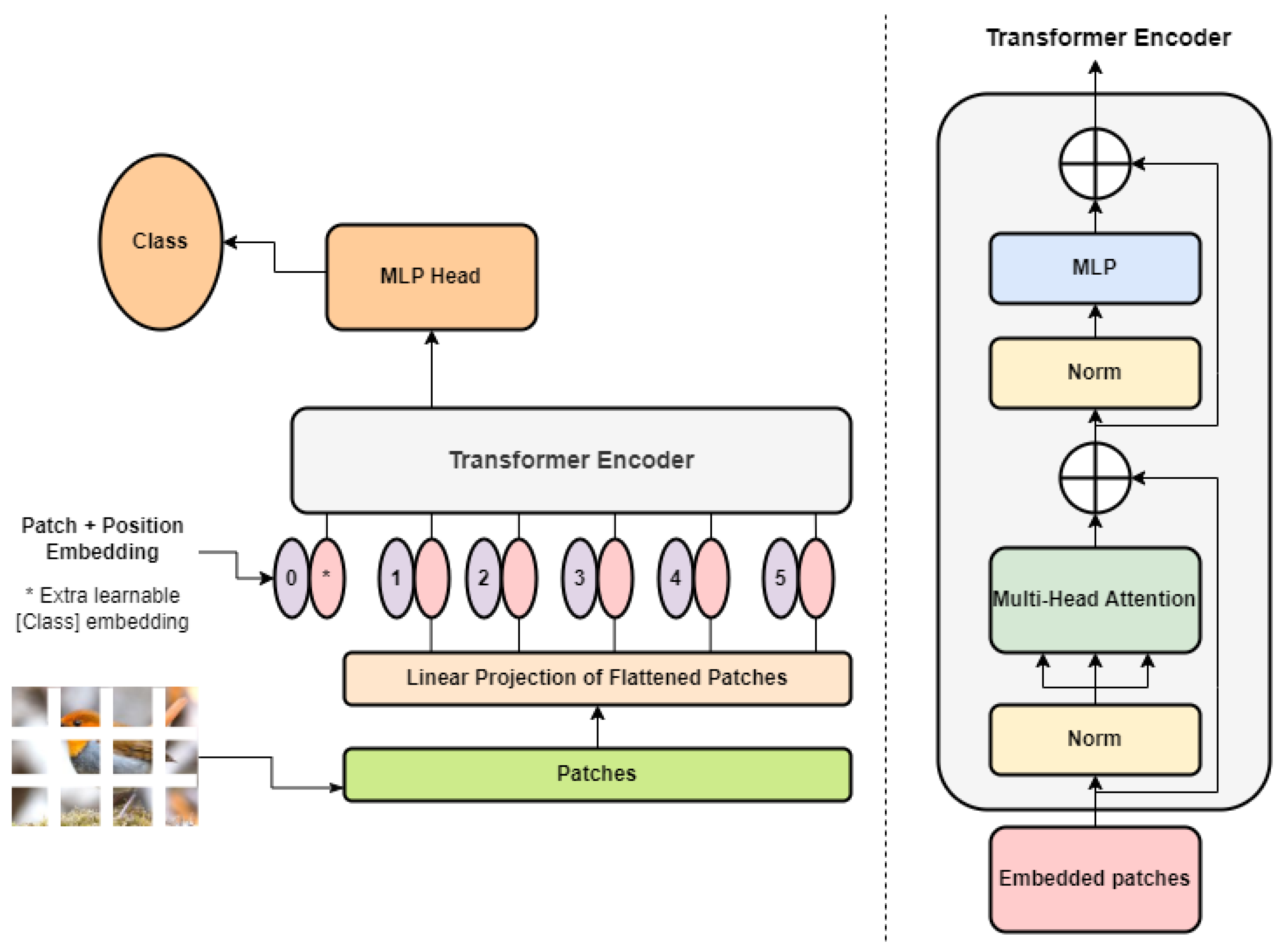
How the Vision Transformer (ViT) works in 10 minutes: an image is worth ...
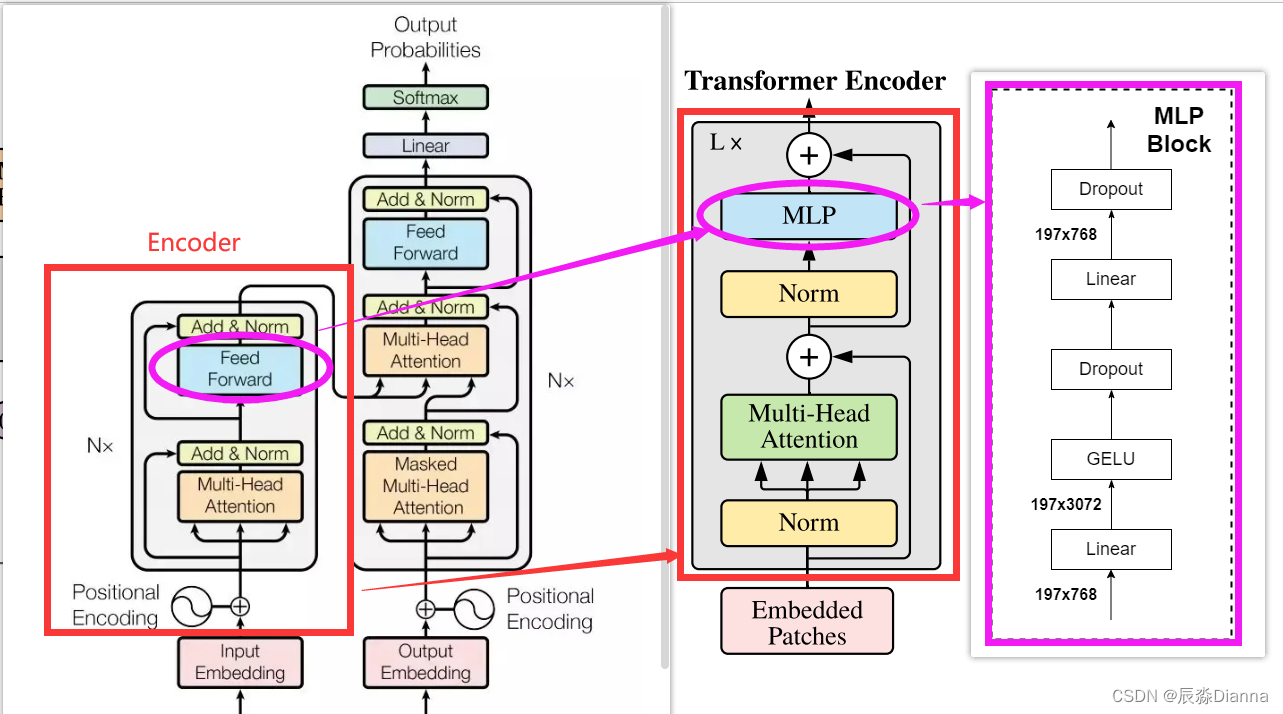
Vision Transformer (ViT)初识:原理详解及代码_vit-transformer代码-CSDN博客
神经网络算法 – 一文搞懂ViT(Vision Transformer) – 人工智能 – 白盒子
AE-ViT: Token Enhancement for Vision Transformers via CNN-based ...
AE-ViT: Token Enhancement for Vision Transformers via CNN-Based ...
Illustration of the proposed Squeeze ViT. (a) An input image is fed to ...
A Hybrid CNN-Vision Transformer Model for Non-Invasive Anemia Detection ...
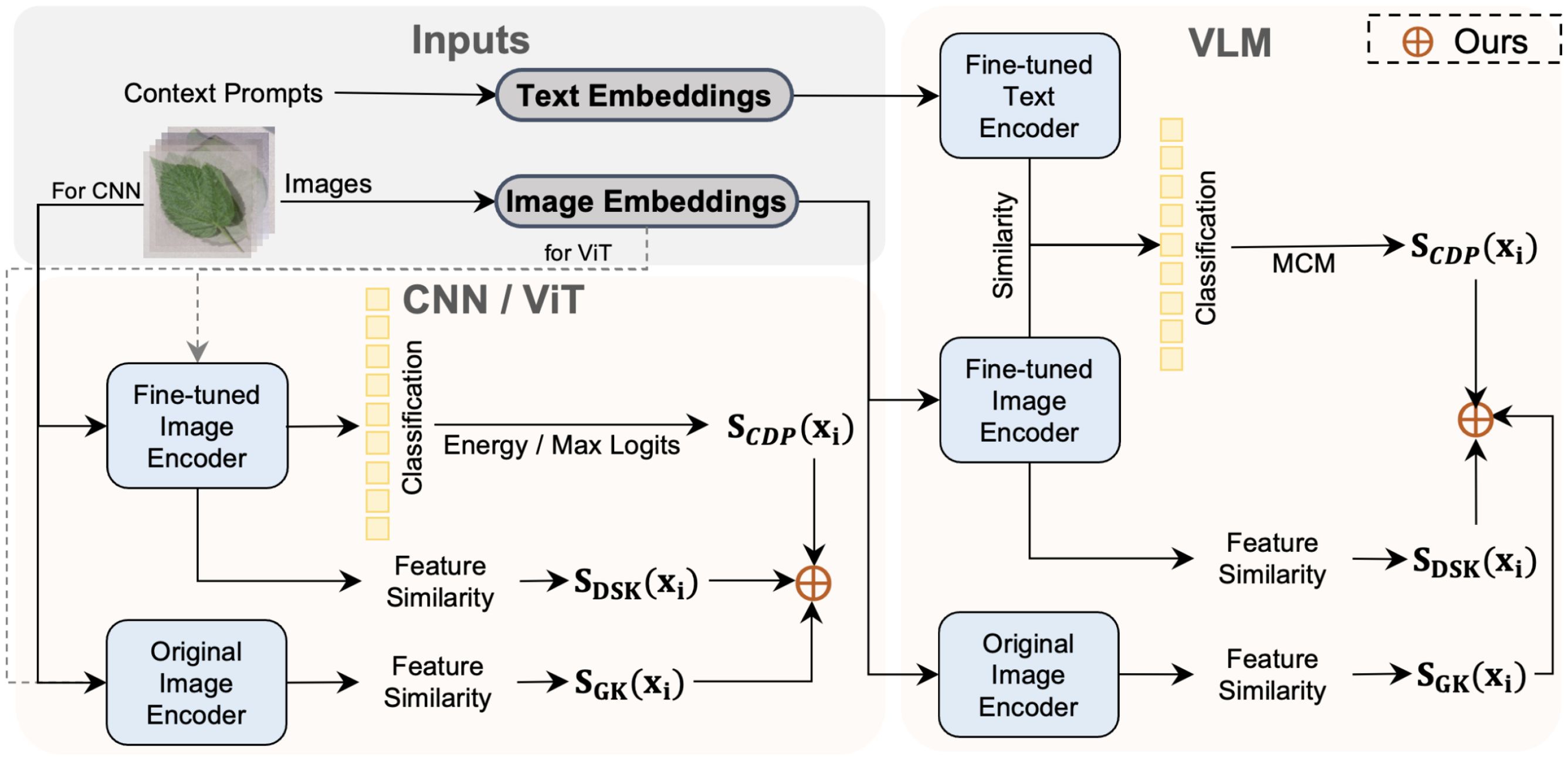
Frontiers | Enhancing anomaly detection in plant disease recognition ...
全网最强ViT (Vision Transformer)原理及代码解析_vit patch embedding-CSDN博客
A Dual-Encoder-Condensed Convolution Method for High-Precision Indoor ...
Comparing Vision Transformers and Convolutional Neural Networks for ...
一文读懂Vision Transformers(ViT):原理详解、使用ViT进行图像识别,构建交互式界面【附源码】_vits 原理-CSDN博客
【算法学习】ViT Adapter——Transformer与CNN特征融合,屠榜语义分割!_vision transformer ...
深度学习模型之CNN(二十一)Vision Transformer(vit)网络详解 | Linvil's Blog
GitHub - emyrael/Hybrid_CNN_VIT_Network: This repository presents a ...
Figure 1 from Hybrid ViT-CNN Network for Fine-Grained Image ...
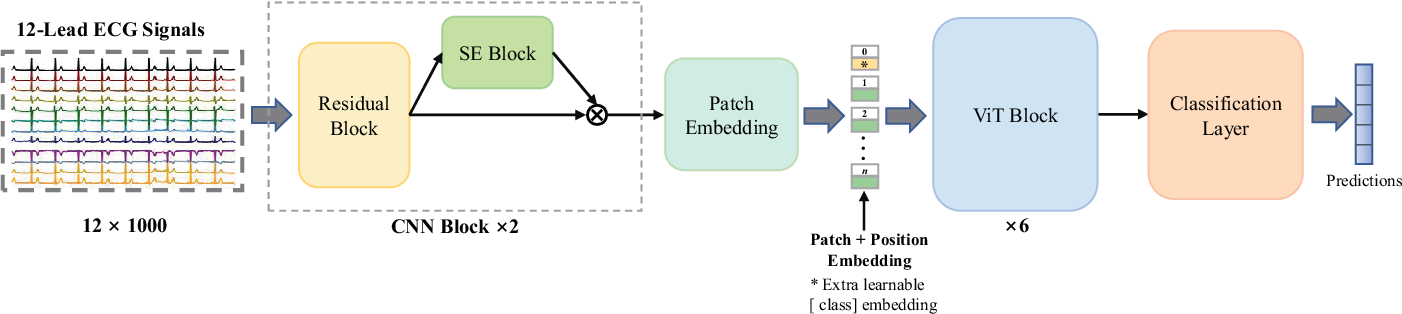
A Multi-Scale CNN-ViT Network with Squeeze-and-Excitation Block for ECG ...
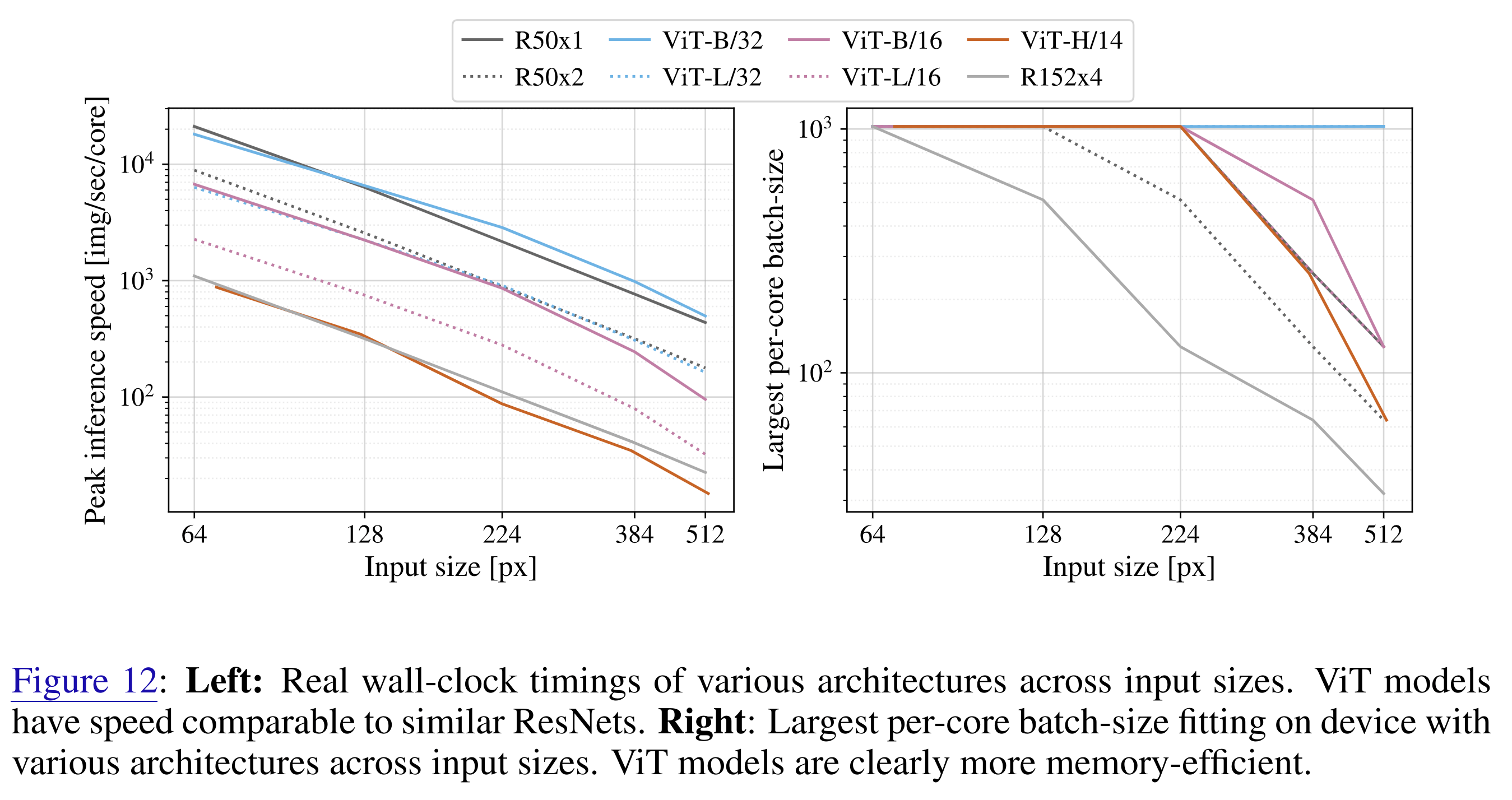
On the speed of ViTs and CNNs
nlpconnect/vit-gpt2-image-captioning | ATYUN.COM 官网-人工智能教程资讯全方位服务平台
(PDF) A survey of the vision transformers and their CNN-transformer ...
[논문 리뷰] AResNet-ViT: A Hybrid CNN-Transformer Network for Benign and ...
Overview architecture of our proposed CrackViT for pixel-level crack ...
CNN의 시대는 끝났는가? Vision Transformer(ViT)의 실제 성능과 산업 현장 적용의 한계
A Novel CNN–ViT Model with Cascade Upsampling for Efficient Crack ...
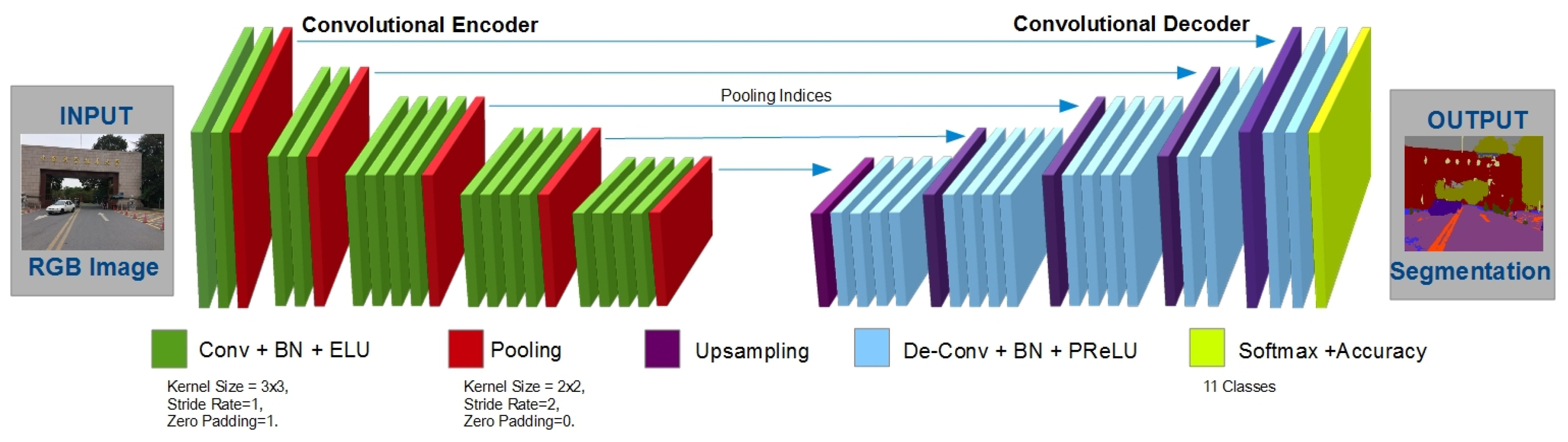
ECRU: An Encoder-Decoder Based Convolution Neural Network (CNN) for ...
The CNN&ViT model architectures, (a) TransUnet (b) TransAttUnet ...
Gating-TinyLLaVA: A Compact Multimodal Model with Dual Visual Encoders ...
A Hybrid ViT-CNN Model Premeditated for Rice Leaf Disease ...
ViT: 简简单单训练一个Transformer Encoder做个图像分类 - 知乎
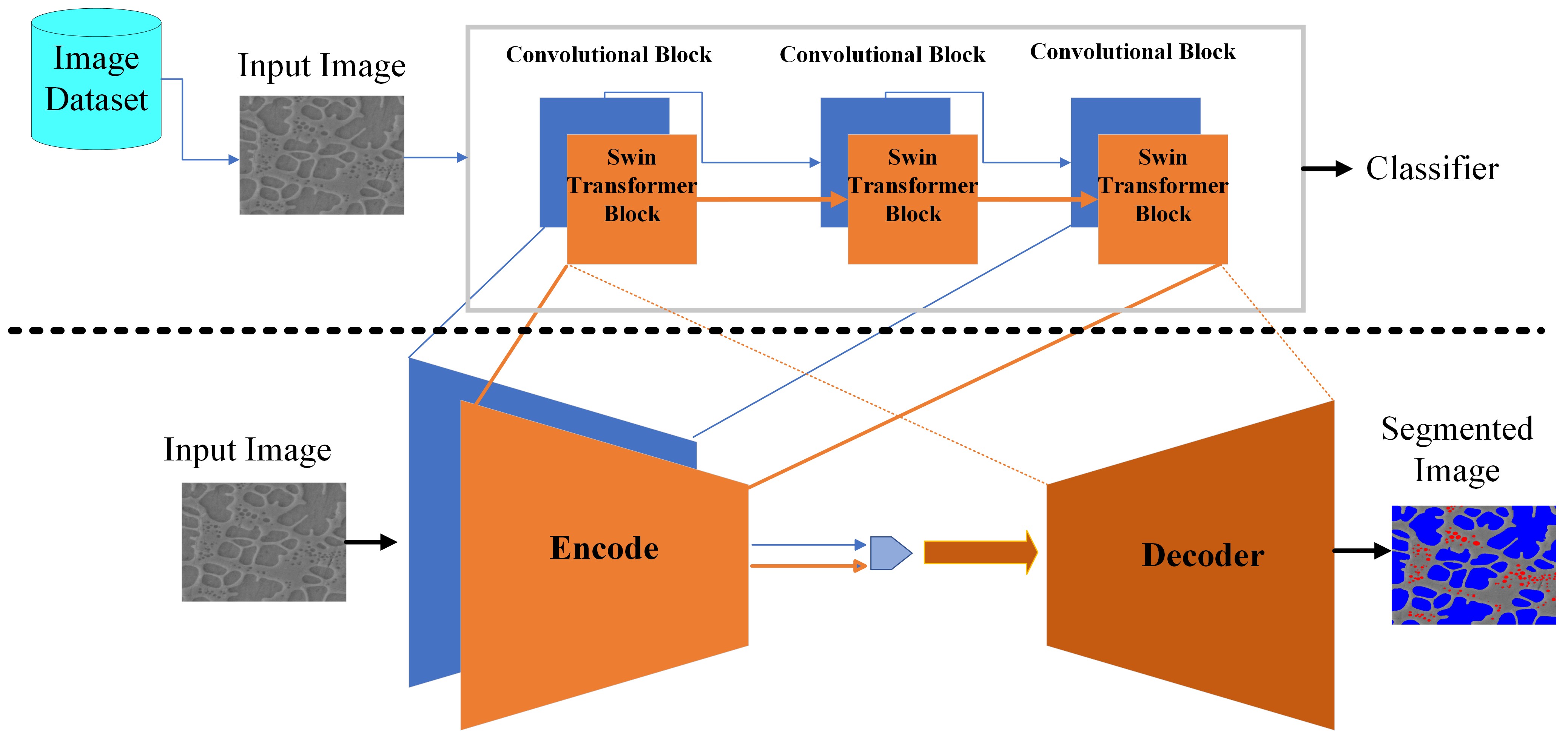
[2308.13917] Transfer Learning for Microstructure Segmentation with CS ...
Performance versus n-CNN-ViT variants; Pure ViT, 1-CNN-ViT, 2-CNN-ViT ...
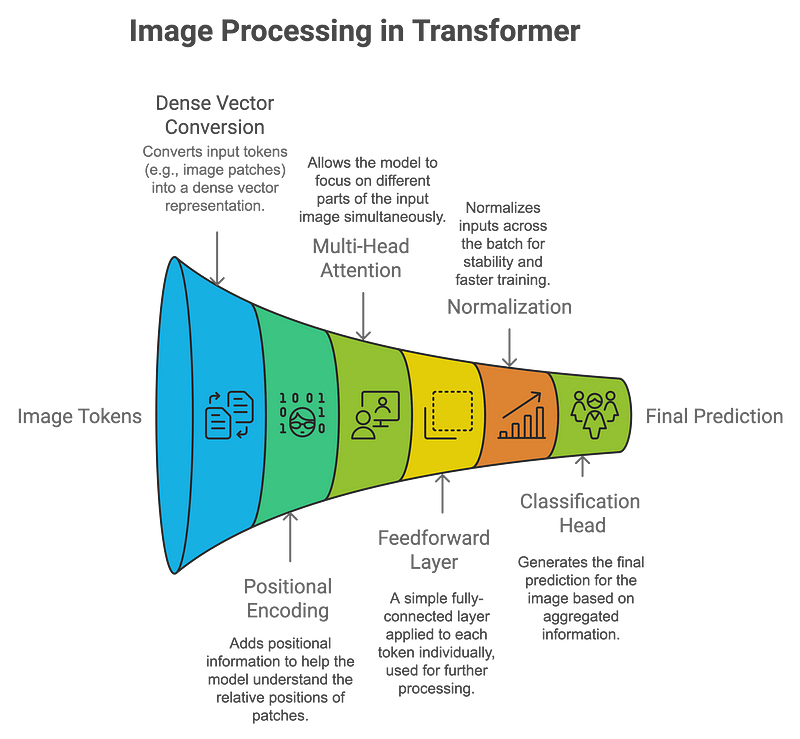
Vision Transformer: A New Era in Image Recognition
Figure 3 from A Multichannel CT and Radiomics-Guided CNN-ViT (RadCT ...
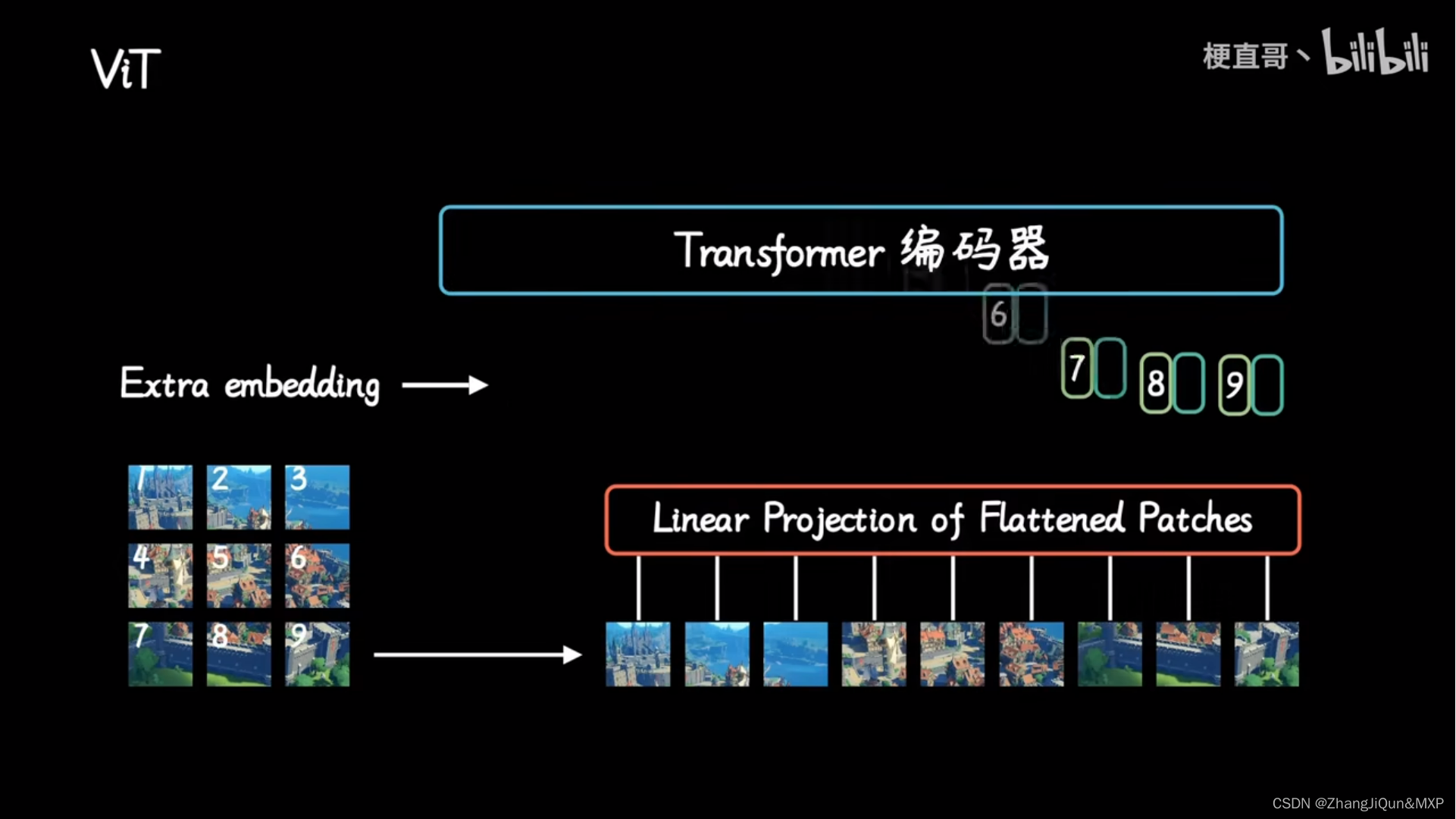
Vision Transformer(ViT)_vit transformer中9个patches的输出是啥-CSDN博客
Image Segmentation Using Vision Transformers (ViT): A Deep Dive with ...
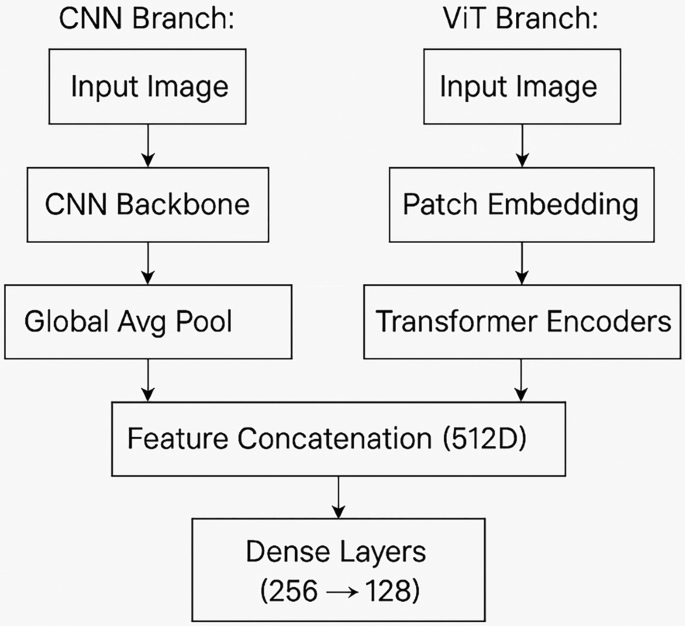
Hybrid CNN-ViT network architecture | Download Scientific Diagram
vit.._vit多头注意力机制-CSDN博客
Compact Vision Transformers — Vision Transformer의 모든 것
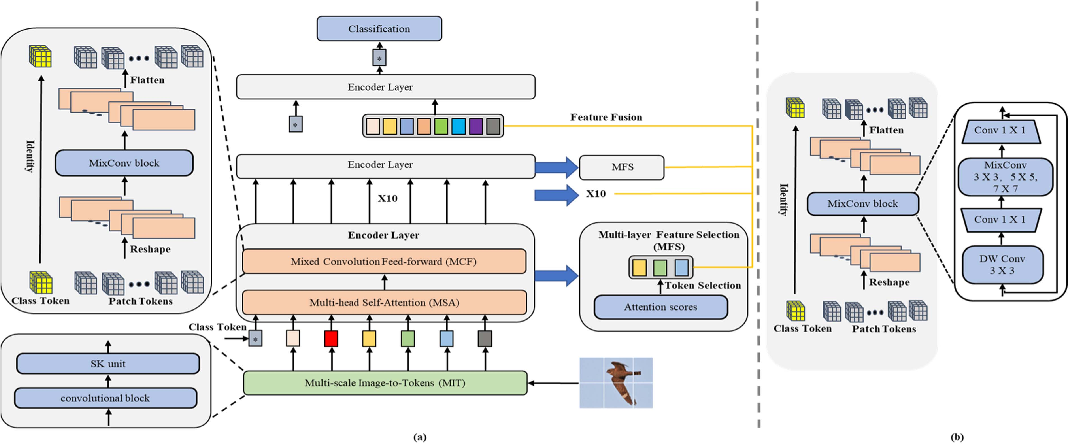
Top: The state-of-the-art ViT-variants [37, 60, 67] use single-scale ...
深度学习模型之CNN(二十二)使用pytorch搭建Vision Transformer(vit)模型 | Linvil's Blog
Transformer在CV领域有可能替代CNN吗?还有哪些应用前景?-轻识
Vision Transformers (ViT) in Image Recognition | Life Zero Blog
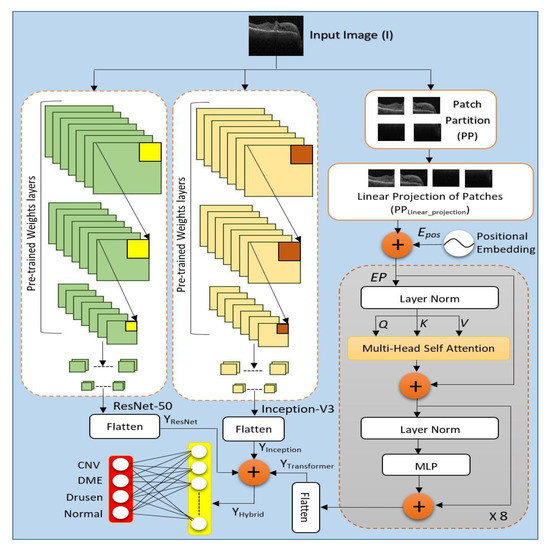
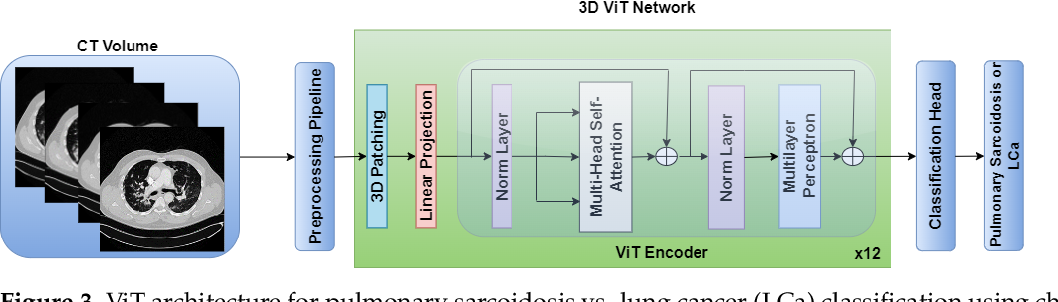
A Multichannel CT and Radiomics-Guided CNN-ViT (RadCT-CNNViT) Ensemble ...
GitHub - AlanLeAI/Hybrid-CNN-ViT-For-Image-Recognition